
Introduction
Implementing the Saga pattern in a Node.js microservices architecture ensures data consistency across services without using distributed ACID transactions. In basic Saga tutorials, one often finds a simple orchestrator calling a few services (e.g. Order, Payment, Inventory) via REST or a message broker, with hardcoded steps and compensating actions. These introductions cover the fundamentals: what Sagas are, the difference between orchestration vs. choreography, and simple examples of local transactions with explicit rollback logic. They demonstrate that a Saga’s lack of automatic rollback requires developers to write compensating transactions for each step.
Common patterns in existing articles: Most tutorials show a central orchestrator service (often a simple Express server or script) using Axios or a message queue to invoke microservice APIs in sequence. They implement a straightforward success path and trigger all compensations if a step fails, usually using try/catch logic. The typical example is an e-commerce order Saga: create order, charge payment, reserve stock, and on failure, cancel the prior steps. Basic best practices like ensuring idempotent operations and defining compensation handlers are usually mentioned. Logging is often just done via console prints for each step, and testing is manual (running the happy path and perhaps one failure scenario). While these resources establish how to implement a Saga, they often omit deeper technical concerns needed for production-ready systems.
Gaps and underrepresented areas: After reviewing numerous Node.js Saga implementations, we found recurring omissions in advanced topics. Little is said about making the orchestrator extensible via middleware or hooks for auditing and metrics, or how one might define Saga flows dynamically outside of code. Many examples avoid mixing asynchronous messaging with orchestration, whereas real systems may blend REST and event-driven steps. Fault tolerance testing, such as systematically injecting failures to verify compensations, is rarely covered beyond anecdotal advice. There is also scant guidance on CI/CD practices – how to version and deploy changes to Saga flows without service disruption. Furthermore, critical operational aspects like observability (structured logging, distributed tracing, correlation IDs) and smart error handling (distinguishing transient vs. permanent failures with automated retries) receive minimal attention in most tutorials. These are precisely the dimensions we will explore in depth.
In this article, we expand on the fundamentals to fill these gaps. All examples will use the Node.js stack (Express for microservice APIs and Axios for calls) to preserve familiarity. We will introduce advanced enhancements – from pluggable orchestrator middleware and dynamic Saga definitions to hybrid messaging, testing strategies, deployment concerns, observability, and robust error handling. The goal is a professional-level understanding of Saga orchestration in Node.js, beyond the simplistic “happy path” demos.
Recap: Saga Orchestration Basics in Node.js
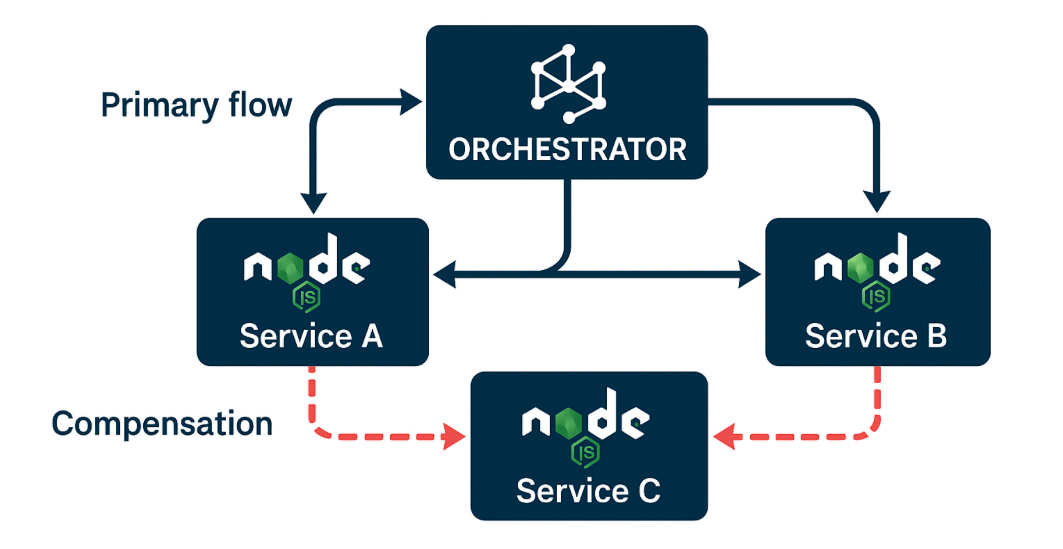
Before diving into the advanced topics, let’s quickly recap the Saga orchestration baseline with Node.js. In an orchestration-based Saga, a central coordinator service directs each step of a multi-service transaction. For example, an Order Saga might involve the following sequence:
- Order Service – Create a new order in Pending status.
- Payment Service – Charge the customer’s payment method for the order.
- Inventory Service – Reserve the items’ stock.
- Notification Service – Send a confirmation email.
If any step fails, the orchestrator triggers compensating actions to undo the previous steps (e.g. refund payment, release stock, cancel the order). This ensures eventual consistency across services. Traditional Node implementations use simple patterns: the orchestrator receives a client request (e.g. an Express route handler), then calls each microservice using Axios (or publishes messages), and catches errors to perform rollbacks. A pseudocode example of a minimal orchestrator flow might look like:
// Pseudo-code for a basic orchestrator flow
app.post('/orders', async (req, res) => {
try {
const order = await axios.post('http://order-service/orders', req.body);
try {
await axios.post('http://payment-service/payments', { orderId: order.id, ... });
try {
await axios.post('http://inventory-service/reserve', { orderId: order.id, ... });
// All steps successful:
await axios.post('http://notification-service/notify', { orderId: order.id, ... });
return res.status(200).json({ status: 'Order Placed' });
} catch (invErr) {
// Inventory step failed – trigger compensation for Payment
await axios.post('http://payment-service/refund', { orderId: order.id });
throw invErr;
}
} catch (payErr) {
// Payment step failed – trigger compensation for Order
await axios.put(`http://order-service/orders/${order.id}`, { status: 'CANCELLED' });
throw payErr;
}
} catch (err) {
console.error('Saga failed:', err);
return res.status(500).json({ status: 'Saga Failed', error: err.message });
}
});
In practice, the above nesting is often refactored for clarity, but it illustrates the core idea: each step’s success allows the Saga to continue, and any failure triggers the necessary compensating calls for prior steps before propagating the error. Idempotency is crucial – both the forward and compensating operations should be safe to retry, as network calls might be repeated or compensations retriggered. For example, calling the payment service’s refund endpoint twice for the same order should have no additional effect after the first success. Ensuring idempotency of operations and rollbacks is a well-covered best practice.
Existing Node.js examples typically hardcode the Saga flow as above. They often use in-memory state (the local variables and try/catch context) to track progress. This is sufficient for a tutorial but flimsy for a real system – a crash of the orchestrator process would lose track of in-flight Sagas. Additionally, simple examples don’t address concurrent saga isolation (ensuring two Sagas don’t step on each other’s partial updates) – a known complexity that advanced implementations or Saga frameworks handle with patterns like Saga Log or state tracking. It’s recommended to maintain a Saga log or state machine to know which steps completed, to resume or compensate after a crash. With these fundamentals in mind, we now move on to the advanced enhancements that elevate a Saga orchestrator from a toy example to a production-grade component.
Extending the Orchestrator with Pluggable Middleware
A key to building a robust Saga orchestrator is designing it for extensibility. In a large system, you’ll want to instrument and augment the Saga’s behavior without cluttering the core logic. This is where pluggable middleware or hooks come in – similar in spirit to Express.js middleware. By allowing custom functions to run before or after each step, or on errors, we can inject cross-cutting capabilities like auditing, logging, metrics, or even custom decision logic.
Auditing & Saga Logs: One useful extension is an audit log that records each step’s outcome. Many real-world saga implementations maintain a Saga Log (or state log) to track progress. For example, the orchestrator can log “Saga started”, “Step 1 (OrderService) completed”, “Step 2 (PaymentService) failed – compensating Step 1” and so forth. This log can be written to a database or persistent store for later analysis. Implementing such logging as a middleware hook means the core Saga execution code calls into the logger at well-defined points (step start, step success, step failure). This provides a clear audit trail of the distributed transaction, which is invaluable for debugging and compliance. Not only does this help during normal operation, but if the system crashes mid-Saga, on restart the Saga Log can be consulted to decide which compensations to run or which step to resume.
Metrics Exporters: Similarly, one can attach a metrics middleware to the orchestrator. For example, a middleware could listen for events like “step completed” or “saga finished” and increment Prometheus counters (e.g. saga_steps_total{service="Payment", status="success"}) or observe durations. By plugging this in, you get automatic emission of metrics for success/failure counts and timing of each Saga step without modifying the Saga’s core logic. Consider a simple implementation using Node’s EventEmitter pattern for the orchestrator:
const EventEmitter = require('events');
class SagaOrchestrator extends EventEmitter {
constructor(steps) {
super();
this.steps = steps; // array of { name, execute(), compensate() }
this.completedSteps = [];
}
async executeSaga(context) {
this.completedSteps = [];
this.emit('sagaStarted', context);
for (const step of this.steps) {
this.emit('stepStarted', step.name, context);
try {
await step.execute(context);
this.completedSteps.push(step);
this.emit('stepSucceeded', step.name, context);
} catch (err) {
this.emit('stepFailed', step.name, err, context);
await this.compensateAllExecutedSteps(context);
this.emit('sagaFailed', err, context);
throw err;
}
}
this.emit('sagaSucceeded', context);
}
async compensateAllExecutedSteps(context) {
// Roll back completed steps in reverse order
for (const step of [...this.completedSteps].reverse()) {
this.emit('compensationStarted', step.name, context);
try {
await step.compensate(context);
this.emit('compensationSucceeded', step.name, context);
} catch (compErr) {
this.emit('compensationFailed', step.name, compErr, context);
// continue with remaining compensations
}
}
}
}
module.exports = SagaOrchestrator;
Now, middleware can be attached by listening to these events. For instance, an auditing plugin can listen to 'stepStarted' and 'stepFailed' events to log entries, and a metrics plugin can listen to 'sagaSucceeded'/'sagaFailed' to report outcomes. This decoupling means you can add new behavior (like sending an alert if a saga fails) without altering the orchestrator’s primary code. It’s analogous to adding cross-cutting concerns in a modular way.
Use case – audit hook: Suppose we want to record every saga step transition to a MongoDB collection for a permanent record. We create a listener:
orchestrator.on('stepStarted', async (stepName, ctx) => {
await AuditLog.create({ sagaId: ctx.sagaId, step: stepName, status: 'STARTED', timestamp: Date.now() });
});
orchestrator.on('stepFailed', async (stepName, error) => {
await AuditLog.create({ sagaId: ctx.sagaId, step: stepName, status: 'FAILED', error: error.message });
});
With this, every time a step starts or fails, a document is written. Likewise, a metrics hook could update in-memory counters or push to a monitoring system. The orchestrator remains agnostic to these extras, simply emitting events at key points.
By designing our Node.js Saga orchestrator with such pluggable middleware, we achieve better separation of concerns. The Saga engine focuses on sequencing and compensation, while observability, auditing, and other policies can be added or removed as needed. This is especially useful as the system grows; for example, you might introduce a metrics exporter (such as pushing custom Saga metrics to Prometheus) only when you need to scale and tune performance, without having had to anticipate it from day one.
Dynamic Saga Definitions from Configuration
In most tutorials, Saga workflows are hardcoded in the orchestrator’s source code (as in our pseudocode earlier). This is straightforward but inflexible – any change to the saga flow (adding a step, reordering services, adjusting timeouts) requires a code deployment. One advanced idea is to support dynamic saga definitions, where the orchestrator reads the saga’s steps from an external configuration, database, or DSL (Domain-Specific Language).
Imagine defining a saga in a JSON or YAML config, or even storing it in a database table, so that product owners or architects can adjust the workflow without touching code. For instance, a JSON saga definition might look like:
[
{
"service": "OrderService",
"action": { "method": "POST", "url": "http://order-service/api/v1/orders" },
"compensation": { "method": "PUT", "url": "http://order-service/api/v1/orders/${orderId}", "body": { "status": "CANCELLED" } }
},
{
"service": "PaymentService",
"action": { "method": "POST", "url": "http://payment-service/api/v1/pay", "body": { "orderId": "${orderId}", "amount": "${amount}" } },
"compensation": { "method": "POST", "url": "http://payment-service/api/v1/refund", "body": { "orderId": "${orderId}" } }
},
{
"service": "InventoryService",
"action": { "method": "POST", "url": "http://inventory-service/api/v1/reserve", "body": { "orderId": "${orderId}" } },
"compensation": { "method": "POST", "url": "http://inventory-service/api/v1/release", "body": { "orderId": "${orderId}" } }
}
]
Here each step lists the service and the HTTP request details for its action and compensation. The orchestrator can load this definition and iterate through it generically: for each step, perform the specified HTTP call (filling in variables like ${orderId} from the context), and if a failure occurs, walk back through completed steps calling their compensation URLs. This approach turns the Saga engine into a form of workflow interpreter. In Node.js, one could implement a simple loader that reads the JSON and produces an array of step objects with execute() and compensate() functions that use Axios to call the given URLs.
The benefit of dynamic definitions is agility – you could add a new service into the saga by updating config, or change an endpoint, without a full redeploy of orchestrator code. It also enables multiple Saga variations: e.g., you could store separate definitions for “StandardOrderSaga” vs “PriorityOrderSaga” and have the orchestrator choose one at runtime based on context. Some teams even store saga definitions in a database so they can be versioned and managed via an internal UI.
However, this power comes with significant caveats. First, you lose compile-time validation – a typo in the URL or method won’t be caught until runtime. Testing becomes crucial for each config change. Second, dynamic flows still need to be handled carefully during deployments (if you update a saga definition in the DB while instances of the old saga are mid-flight, how do you handle that?). A safe strategy is to include a version number in saga definitions. For example, keep old versions in the system and mark them as deprecated only after running sagas complete. The orchestrator can explicitly request a certain version of the saga config when starting, to ensure consistency through one transaction.
Another challenge is implementing conditional logic or loops in a data-driven saga. Most simple config formats don’t capture branching well. For complex logic, a code-based saga or a full-fledged workflow engine might be more appropriate. Nonetheless, dynamic saga configuration is an underexplored area that can bring flexibility. Even if you don’t expose it to non-developers, you might internalize it: for example, define saga flows in a separate YAML file in your repo, which engineers can modify without touching the core orchestrator code. This keeps the orchestration engine generic.
In summary, reading saga definitions from config/database can turn your Node.js orchestrator into a mini workflow engine. It fills a gap where most Node examples hardcode one specific flow. Just be mindful of complexity: start by externalizing simple aspects (like timeouts, or endpoint URLs) before graduating to fully dynamic workflows. In practice, some teams eventually adopt dedicated orchestration frameworks (like Netflix Conductor or Temporal) when dynamic workflow needs grow, but if you want to preserve the Express/Axios stack, a carefully managed config-driven Saga could be a happy medium.
Incorporating Asynchronous Messaging Within Orchestration
Many Node.js saga implementations choose either a pure request/response style (synchronous HTTP calls) or a pure event-driven style (using a message broker and choreography). However, real-world systems can benefit from hybrid approaches: using asynchronous messaging within an orchestrated saga for certain steps, without fully switching to a choreography model. In other words, the orchestrator remains in control of the saga’s logic, but some communications to services happen via a message broker (e.g. Kafka or RabbitMQ) rather than direct HTTP calls. This can be useful for long-running or non-blocking interactions, or to interface with services that are inherently event-driven.
Why mix messaging? Suppose one step of your saga triggers a process that might take a long time or should be handled offline – for example, generating a detailed report or performing an external credit check. You might not want the orchestrator to hold an open HTTP request waiting for this to finish. Instead, the orchestrator can publish a command to a message broker (Kafka topic, RabbitMQ queue, etc.) for that service and then pause waiting for a response event. The saga continues when the response message is received. This achieves asynchronous decoupling for that step, yet the overall sequence and compensations are still centrally managed by the orchestrator.
Example scenario: In our order saga, imagine a “Fraud Check Service” that must approve the payment before shipping. The orchestrator could post a message like fraud_check_requested to a Kafka topic that the Fraud service consumes. Meanwhile, it listens (with a timeout) for a corresponding fraud_check_completed event. If the event comes back positive, the saga proceeds to Inventory; if it comes back negative or times out, the saga aborts and compensates (perhaps canceling the payment). The orchestrator effectively orchestrates via events in this step. An orchestration flow can thus have a mix: some steps are synchronous HTTP (fast, simple calls) and others are asynchronous via events.
Node.js makes event handling relatively easy with libraries like amqplib for RabbitMQ or kafkajs/node-rdkafka for Kafka. A step implemented with Kafka might look like this:
// Pseudo-code for an orchestrator step using Kafka
await kafkaProducer.send({ topic: 'fraud_requests', message: { orderId } });
const result = await waitForKafkaResponse('fraud_responses', orderId, 5000); // wait up to 5s
if (result.status !== 'APPROVED') {
throw new Error('Fraud check failed');
}
Here, waitForKafkaResponse would be a helper that subscribes to the fraud_responses topic and filters for a message with the given orderId (acting as a correlation identifier). Under the hood, it might resolve a promise when the matching message arrives or reject if the timeout elapses. The orchestrator is still in charge—it’s just using Kafka as the transport for that interaction. This pattern requires designing a correlation scheme (e.g., using the order ID or a saga ID in the messages so the orchestrator knows which saga the response belongs to) and possibly a temporary state (the orchestrator might need to store that it’s waiting for fraud check result in the Saga Log, in case it restarts).
Hybrid orchestration advantages: By leveraging messaging, we gain resiliency and decoupling. The orchestrator can, for instance, persist its state before sending the message and not worry if it crashes while waiting – on restart it could resume from the waiting point if it has the Saga Log. It also avoids tying up HTTP threads for long waits, which is important in Node’s event loop model to maintain high throughput. In fact, using a message broker can improve the durability of the saga: one article notes that the orchestrator can persist events to a broker like Kafka for durability (the orchestrator can replay or continue from them later). This approach meets the Durability aspect (the “D” in ACID, minus the I for isolation) by having a reliable log of what happened via the message broker.
Without migrating to full choreography: The key here is we do not let each service freely publish and subscribe to events without coordination. The orchestrator still explicitly tells each service what to do (even if the telling is via an event) and expects a specific outcome message. This avoids the uncontrolled “event storm” that a naive choreography can lead to, while still reaping benefits of async communication. Essentially, we are implementing a request/reply pattern over a message bus, under orchestration’s umbrella.
One caution is that the orchestrator logic becomes more complex when handling async steps. You’ll need to manage timeouts and what happens if a response never comes. For example, if Fraud Check doesn’t respond in 5 seconds, do we assume it failed and compensate payment? Possibly yes. Also, orchestrator should handle duplicate or late responses (e.g., if a response comes after a timeout and after compensation, perhaps just log it and ignore). Using a correlation ID in messages is mandatory so you don’t confuse responses from multiple concurrent sagas. We’ll discuss correlation IDs more in the observability section, but note that the orchestrator can generate a unique saga ID and include it in every message or HTTP header it sends, to trace the saga.
In Node.js, implementing the waiting on a message can be done with an event emitter or simply by writing the orchestration in an async function that awaits a promise which is resolved by the message consumer. Some developers choose to use more advanced libraries or even actor model frameworks for handling these long waits, but it can be achieved with core Node patterns (for instance, setting up a Kafka consumer that pushes events into a Map of pending saga promises).
This hybrid model is underrepresented in tutorials because it’s more complex than either pure REST or pure events. But it’s a powerful approach in practice – you might use HTTP for quick calls and reserve messaging for steps that involve human interaction, slow processes, or bridging to an event-driven component. The result is a more resilient saga: even if a service is briefly unavailable, the message will queue until it can process it (improving reliability over synchronous calls). Just remember to implement the necessary safeguards: time-out or retry waiting for replies, and design compensations for cases where a reply eventually comes but the saga already timed out (for example, if the fraud check approves late, you might need to send a follow-up “cancel that approval” event because the order was already canceled).
In summary, asynchronous messaging inside orchestration combines the centralized control of an orchestrator with the decoupling of event-driven communication. It’s a best-of-both-worlds technique that addresses scenarios which pure REST sagas struggle with, without losing the clarity of having one orchestrator dictate the flow.
Testing Rollback Logic with Fault Injection
One area where many saga examples are notably weak is testing – especially testing the failure paths and compensations. In a distributed saga, there are numerous points of failure: any service call can fail, and even compensating calls can fail. We need strategies to systematically verify that our orchestrator and services handle these failures correctly. This is where fault injection and careful testing come in. Rather than hoping our saga compensation works, we should actively simulate failures in a controlled environment to see what happens.
Why testing is challenging: The saga involves multiple services and asynchronous steps, so replicating a failure scenario means either mocking those services or creating a test environment where we can deliberately cause certain calls to fail. It’s not enough to test the happy path – you must test that if service B fails, then A’s compensation runs; if service C fails, then A and B compensations run, etc. As noted in one discussion of Saga pitfalls, designing and testing compensation logic requires simulating various failure scenarios to ensure everything works as expected. This can be labor-intensive, but it’s essential for confidence in your system’s resilience.
Approach 1: Unit testing with mocks/stubs. For the orchestrator code, we can abstract the actual service calls (Axios calls or message sends) behind an interface, so that in a test we can stub out a failure. For example, instead of calling Axios directly in the orchestrator, we call a services.order.create() function. In tests, we then mock services.order.create to throw an error when we want to simulate a failure, and verify that the orchestrator then called services.payment.refund() as compensation, and ultimately threw the error up. Node.js testing frameworks like Jest can easily stub functions and also fast-forward timers if needed (for testing retry logic or timeouts).
We should write test cases for each step’s failure. For a saga with N steps, you’d have at least N test cases, each one failing step i and expecting that all steps 1…i-1 have their compensations invoked. It’s also worth testing the scenario of a compensation failing – e.g., what if the Payment refund itself errors out? Ideally the orchestrator should catch that and perhaps log an alert (compensation failures often require manual intervention, as you’re already in a failure scenario).
Approach 2: Integration testing in a sandbox environment. Unit tests are good, but they might not catch issues with the real HTTP calls or message timings. A step further is to spin up the actual services (or lightweight dummy versions of them) and run a saga end-to-end. This can be done in a local environment using Docker Compose or similar to bring up all services and the orchestrator. Then write a test (using a tool like Mocha or even a simple script) that hits the orchestrator’s endpoint and observes outcomes. To simulate failures in this setup, you can instrument the dummy services to provide a special trigger. For instance, the Inventory Service could check for a flag in the request (like a product name “FAIL_TEST”) and deliberately return an error to simulate a failure at that point. Then the orchestrator should perform compensations. The test would verify the final response and perhaps query the database states to ensure rollbacks happened.
Another integration strategy is using fault injection tools or chaos testing. In microservices, chaos engineering (randomly killing containers or introducing network latency) is used to ensure the system can handle unexpected failures. You can adapt this approach to sagas by, say, configuring a chaos monkey to terminate one of the service instances at the moment the orchestrator is about to call it. This would test that your orchestrator properly handles a connection failure (likely by treating it as a step failure and compensating). While full-blown chaos testing might be beyond early-stage development, it’s an excellent way to validate saga robustness in staging environments. In fact, experts recommend actively testing how the system behaves if any saga step fails – essentially performing fire drills for your compensations.
Automating regression tests: Incorporate saga failure scenarios into your CI/CD pipeline. Each time you update the orchestrator or related services, run a suite of saga tests. For example, after deployment to a staging environment, you might have automated tests that start a saga and artificially fail step 2, then check that the outcome is a fully rolled-back state with appropriate responses. This ensures that as you modify code, you don’t accidentally break the compensation logic. It’s easy for a change in one service’s API to break a compensation call if not caught – e.g., if the Refund API changes its contract and the orchestrator isn’t updated, your saga might not compensate properly. Automated tests can catch this early.
Use of Saga Logs in testing: If you implemented a Saga Log (audit trail), you can leverage it in tests. After a test saga execution (especially for failure cases), query the Saga Log to verify it contains the expected sequence of events: e.g., “Step1 Complete, Step2 Failed, Compensate1 Complete”. This not only validates functionality but also ensures your logging is working for when you need it in production. One Medium article explicitly recommends to “Implement a Saga Log … [and] Test Failure Scenarios” as best practices. Doing so will pay off in easier troubleshooting later.
In summary, testing saga rollbacks is non-trivial but absolutely necessary. Use a combination of unit tests (to simulate and verify orchestrator behavior in isolation) and integration/chaos tests (to see the whole system respond to failures). By proactively injecting faults, you gain confidence that when a real failure occurs at 3 AM, your Saga will do the right thing – and if not, you’ll have the observability to diagnose what went wrong.
CI/CD Considerations: Versioning and Deployment of Sagas
Implementing sagas is one challenge; evolving them over time is another. As your microservices architecture grows, you may need to update saga logic – for example, adding a new step (maybe a new service to call as part of the transaction) or changing the order of steps. Coordinating these changes in CI/CD deployments is critical to avoid inconsistencies. Unlike a monolithic transaction, a saga’s flow is distributed and tightly coupled to multiple services’ capabilities. An orchestrator change can affect many services, so it must be managed carefully. Let’s outline best practices around versioning, compatibility, and rollout of saga changes.
Versioning Saga Flows: One strategy is to explicitly version your sagas. If you introduce a new Saga definition that’s not backward compatible with the old (for instance, it calls a new service that older orchestrator didn’t, or expects a new response), treat it as “Saga v2”. The orchestrator could potentially handle both versions for a transitional period: e.g., new orders use Saga v2, but any in-flight or pending transactions started with v1 are completed with v1 logic. If you externalize saga definitions (as discussed earlier), you might include a version field and keep the old config around until no v1 sagas remain.
In code, this might mean the orchestrator has branching logic: if an incoming request is marked or decided to use the new flow, run the new sequence, else run the old. Alternatively, spin up a new orchestrator instance (or container) that handles v2 while the old one handles v1, and gradually route traffic to v2. This is analogous to API versioning. The need arises because sagas often span a time window – consider a long-running saga that might take minutes or hours (if waiting on some external event). You can’t instantly swap out the logic without potentially stranding those transactions.
Schema compatibility: When deploying changes, deploy in an order that doesn’t break running sagas. For example, say you add a call to a new microservice in the middle of the saga. If you deploy the orchestrator change before the new service exists or is ready, any saga instances reaching that step will fail unexpectedly. Conversely, if you deploy the service first but the orchestrator isn’t sending it requests yet, that’s generally fine. So a rule of thumb is: deploy new services or new endpoints first, orchestrator logic second; and for removals, remove orchestrator calls first, then deprecate the service endpoint. This ensures the orchestrator never tries to call a service that isn’t ready. In practice, this might involve feature flags – e.g., the orchestrator could include the new step but guarded by a config flag that is turned on only after the new service is confirmed up in production.
Automated regression in CI: We touched on testing earlier – make sure those tests run in your CI pipeline. If you have a robust suite of saga scenario tests (including failure cases), treat them as gating criteria for release. This helps catch integration issues between orchestrator and services. For instance, if the Payment service’s API changed its request format, the CI tests should catch that the orchestrator’s Axios call got a 400 Bad Request, before you deploy to prod.
Database transactions and sagas in CI/CD: An interesting aspect is if your saga steps involve database changes (most do), how do you handle partial updates during a deployment? One pattern is the Transactional Outbox or similar, which ensures a service either fully publishes its event or none at all. During a deployment, you might want to quiesce the system (drain requests) or at least the orchestrator to ensure no saga is mid-flight while its code is being swapped. A rolling deployment of the orchestrator with careful coordination can achieve zero-downtime if designed well: e.g., the orchestrator could use a persistent queue for pending saga commands so that a new instance can pick them up. If using stateless orchestration (no in-memory state, everything in Saga Log), then you can more easily run multiple orchestrator instances and update them one by one (the new code will read the Saga Log and continue flows seamlessly if it’s backward compatible).
Continuous Delivery of Saga Orchestrator: Treat the orchestrator as a first-class service in your microservice ecosystem. It should have its own CI/CD pipeline. Enforce code reviews with a checklist that asks: “If this change fails at step X, are compensations still correct? Do we need to update any compensation due to this change?” Also, when adding new steps, ensure compensations for the new step are defined and tested as well.
Rollout strategies: If possible, use canary releases for saga changes. For example, deploy the new orchestrator version for a small percentage of traffic (say, 5% of new orders) while others still go to the old version. Monitor the outcomes – are sagas succeeding, any increase in failures? Because sagas amplify errors (a bug can cause multiple compensations and cross-service effects), a flawed saga logic can be costly. A cautious rollout can prevent a widespread incident. If your orchestrator is behind an API gateway, you could route a fraction of requests to the new one based on a header or user segment.
Another subtle aspect: orchestrator as single point of coordination – ensure high availability during deploy. If you only have one instance and you take it down to update, no new sagas can start (and maybe in-progress ones fail if they were relying on it). Always run multiple instances (with sticky session if needed for in-memory, or better, stateless with centralized log/state) so that you can update one while others handle traffic.
Finally, document your saga flows and any changes for the team. Sagas have many moving parts; a new team member should be able to find a flow diagram of the saga and understand what happens if something fails. Keeping such documentation updated as part of your deployment process is a good practice.
In short, treat saga modifications with the same care as API changes. Introduce versioning to handle transitions, deploy in the right sequence (additive changes first, removals after), use CI tests as guardrails, and monitor new releases closely. With these practices, you can evolve your saga orchestrations safely even as your business requirements grow and change.
Observability in Saga Orchestration: Logging, Tracing, and Correlation
A saga by nature is a multi-step, multi-service process – which makes observability crucial. When something goes wrong in a saga (or even when it succeeds!), you want to be able to trace the entire journey across services, see what happened at each step, and diagnose any issues. Observability in this context includes logging, metrics, and distributed tracing, all tied together with correlation IDs. Let’s dive into how to integrate these in a Node.js saga orchestrator and the participating services.
Structured Logging and Correlation IDs: It’s highly recommended to use structured logs (e.g., JSON logs) in both the orchestrator and microservices, including key metadata like a correlation ID. A correlation ID is an identifier (often a GUID/UUID) that tags all messages and log entries for a given transaction (saga). By generating a unique ID at the start of a saga and passing it along to each service (usually via an HTTP header like X-Correlation-ID), you create an “invisible thread” that ties together all logs from different services. This way, if an order saga fails halfway, you can search logs across services for that correlation ID and reconstruct the timeline. As one guide suggests: “Use structured logging (e.g., JSON format) to capture events and metadata. Include correlation IDs in logs to trace workflows across services.”. In practice, you can implement this by having an Express middleware on the orchestrator that generates a correlationId (if the incoming request doesn’t have one) and attaches it to req and response headers. The orchestrator should send this ID in an X-Correlation-ID header on every Axios call to microservices. The services, in turn, should propagate it when they call others, and include it in their own logs. Many logging libraries for Node (like Winston or Pino) allow adding contextual fields (like correlationId) to every log entry, making this easier.
Distributed Tracing: While logs are great, in complex distributed transactions, tracing tools like OpenTelemetry, Jaeger, or Zipkin provide a bird’s-eye view of the saga’s path. The orchestrator can start a distributed trace span when it receives a saga request, then start sub-spans for each step/call, and end the span when the saga completes or fails. By using OpenTelemetry’s Node.js SDK, for example, you can create a trace with a unique trace ID (which could double as your correlation ID). Each microservice, if instrumented with OpenTelemetry, will join the trace when it sees the trace context headers from the orchestrator’s Axios call (these are standard headers like traceparent). The result is a visual timeline of the saga: you can see a trace with spans for “OrderService invoke”, “PaymentService invoke”, “InventoryService invoke”, etc., with their durations and whether they succeeded or errored. This is immensely helpful for debugging and performance tuning. It lets you answer questions like: which step took the longest? Did a particular service cause a slowdown? If a saga failed, at what step and why? A good distributed tracing setup will even show logs or error details attached to spans. As a reference, it’s advised to “implement distributed tracing (e.g., with OpenTelemetry) to track events across services, and annotate spans with relevant data for better insights.”. In our Node orchestrator, that means labeling spans with saga IDs, step names, or outcome (to quickly spot which span failed).
Metrics and Monitoring: We touched on metrics earlier under middleware, but let’s reiterate with observability in mind. Define and collect metrics like:
- Saga throughput: number of sagas started, succeeded, failed per minute (
sagas_started_total,sagas_failed_total). - Step success/failure counts per service: e.g., how often does Payment succeed vs fail as part of a saga (
saga_step_success{service="PaymentService"}etc.). This can highlight if a particular service is a common point of failure. - Saga duration: how long do sagas take end-to-end, perhaps segmented by outcome. You might have a histogram for saga completion time. If you notice sagas taking longer over time, that might indicate a bottleneck.
- Compensation rate: what fraction of sagas trigger compensations (fail at least one step)? A high rate could signal instability in some downstream service.
- Queue lengths / backlog (if using messaging): e.g., size of Kafka topics or pending messages for saga responses. This helps detect if orchestrator is waiting on slow responses.
In Node.js, you can use something like the prom-client library to record custom metrics and expose an endpoint (like /metrics) that Prometheus can scrape. For example, increment a counter saga_failed_total in the orchestrator’s catch block for saga failure. Also consider metrics in each microservice: e.g., each service can have a counter for how many times it had to perform a compensating action. Monitoring these metrics over time is crucial – if you deploy a new version and suddenly the compensation rate doubles, you caught a problem early.
Logging every step: The orchestrator should log each step transition in detail (preferably at INFO level for normal operations). For example: “Saga 123: Calling PaymentService for order 456”, “Saga 123: PaymentService responded with 402 Payment Declined – initiating compensation”, “Saga 123: Rolled back OrderService (order 456 cancelled)”. These kinds of messages, with the correlation ID and saga ID, make the sequence of events clear in text form. A well-logged saga means when something goes wrong at 2 AM, the on-call engineer can follow the bread crumbs in the logs and pinpoint where it went off track. Make sure to also log the payload identifiers (like order IDs, user IDs) to assess impact (“which order failed?”). However, avoid logging sensitive data or huge payloads – just log references/IDs and summary info to keep logs useful.
Audit vs debug logs: In production, verbose debug logging of every detail might be too much, but you should at least have audit-level logs (one per step as above). You can always elevate to debug logs in a troubleshooting scenario to see raw request/response data if needed.
Using Saga Log for observability: If you implemented a Saga Log table (audit log), that’s also an observability tool. It can be queried to answer: “how many sagas are in progress right now, and at what step?” or “show me all sagas that failed in the last day and which step they failed on.” In a GUI, you could even build an admin panel to view saga states. This goes beyond traditional logging by making the saga state queryable. It’s optional but can greatly aid in operational oversight.
In conclusion, integrating comprehensive observability into your saga orchestration is not just nice-to-have – it’s necessary for a reliable system. Use correlation IDs to link events, leverage distributed tracing for a holistic view of the transaction, and gather metrics to monitor health. When combined with the earlier suggestions (pluggable middleware hooks for logging/metrics, saga logs, etc.), you end up with a Saga implementation where issues can be detected and diagnosed quickly, rather than a black box that’s hard to troubleshoot.
Advanced Error Handling: Classification and Automated Retries
In a distributed saga, not all errors are equal. Some failures are transient and may succeed if retried, while others are permanent business logic failures that no retry can fix (and thus should trigger immediate compensation). A sophisticated orchestrator can distinguish between these cases and handle them appropriately. Additionally, by integrating patterns like exponential backoff retries and circuit breakers, we can make the saga more resilient to intermittent issues without human intervention.
Error classification: Consider two scenarios – (1) a network timeout occurs calling the Payment service, and (2) the Payment service responds “card declined”. In scenario (1), the service might be temporarily unreachable or slow; if we try again in a few seconds, it might go through. In scenario (2), however, the business outcome is a definite failure (the card is invalid or lacks funds) – no amount of retrying will change that unless the user provides a new card. The orchestrator should detect these and react differently. Concretely, when an Axios request fails, you get either an exception (for network errors/timeouts) or a response with an error status. You can inspect error.code (like ECONNREFUSED, ETIMEDOUT) and HTTP status codes. One approach:
- If the error is a network error or 5xx server error, classify as transient.
- If the error is a 4xx client error (especially a known business error code like 402 Payment Required or 409 Out of Stock), classify as business failure.
- Some errors might be in a gray area (e.g., a 503 Service Unavailable could be transient or could mean the service is down for a longer period; often treat as transient up to a retry limit).
Once classified, the orchestrator can decide: for a transient error, retry the step (after a short delay), whereas for a business error, don’t retry, initiate compensation immediately. Implementing this in Node.js could be as simple as wrapping Axios with a utility that attempts a few retries for certain conditions. For example, using the axios-retry library or writing a loop:
async function callWithRetry(config, retries = 3) {
for (let attempt = 1; attempt <= retries; attempt++) {
try {
return await axios(config);
} catch (err) {
const transient = isTransientError(err);
if (!transient) throw err; // non-transient, throw immediately
if (attempt < retries) {
const backoff = 100 * Math.pow(2, attempt); // exponential backoff
await sleep(backoff);
continue; // retry
}
throw err; // exhausted retries
}
}
}
Here isTransientError(err) would contain logic like: if err.code is ECONNRESET or ETIMEDOUT or response status is >=500, return true; if response status is 4xx (except perhaps 429 Too Many Requests, which might be transient in a different sense), return false. By doing this, a glitchy network doesn’t immediately bring down the saga. Indeed, one set of guidelines suggests handling transient failures with retries and backoff. For example, if a service is momentarily unreachable, the orchestrator could log a warning and try again in a few seconds rather than failing the whole saga at once.
Automated rollback triggers: In contrast, when an error is classified as permanent (business rule violation), you want to fail fast and start compensation. It might even be that the service itself signals a compensatable failure. For instance, the Payment service might return a special status or error code indicating “Payment declined – do not retry”. The orchestrator could map that to immediately trigger the payment compensation (refund) and overall saga failure. Some designs incorporate an error catalog – a list of error types or codes that are considered retryable vs not.
Circuit Breaker for stability: If a particular service is repeatedly failing (say Inventory service times out 90% of the time due to heavy load), constant retries from many concurrent sagas could actually worsen the load (known as retry storm). Implementing a circuit breaker pattern helps prevent this. In Node.js, libraries like opossum provide circuit breaker functionality. The idea is that if a service has a high error rate, the orchestrator (or a proxy in front of the service) “opens” the circuit and stops sending requests for a short cool-off period. During that time, any attempt to call that service fails fast (giving it time to recover). The orchestrator could integrate a circuit breaker around each Axios call. For example, wrap the axios call in a breaker that monitors failures. If open, decide whether the saga should wait or fail. In a saga, probably best to fail that step quickly when the breaker is open (since the service is known down) and do compensation; or possibly design the saga to pause (not common unless you can wait long). Most often, circuit breaker is about protecting the system from overload. As Dinesh Arney notes, use circuit breakers to prevent cascading failures in sagas – for instance, if Payment is down, failing fast prevents all orders from hanging on Payment calls.
Idempotency and retries: We must reiterate the importance of idempotency here. If the orchestrator is going to retry a step, that step must be safe to do multiple times. That often requires the microservice to handle duplicate requests gracefully. For example, if the Payment service receives the same payment request twice due to a retry, it should detect the duplicate (maybe by order ID) and not double-charge. Or if Inventory reserve is called twice for the same order, the second attempt should realize stock is already reserved and simply succeed (or return a benign response). Designing services to be idempotent is a prerequisite for safe retries.
Automating retries for certain failure types: You can encode policies per step or per error type. For instance, you might decide that if Payment fails due to a network error, try up to 3 times, but if Inventory fails due to “not enough stock” (business rule), don’t retry at all. Another example: if an email notification fails (maybe the email server is down), you might classify that as a less critical transient error – you could even choose to not fail the entire saga but simply log and continue (depending on requirements). Advanced orchestrators allow such nuanced policies, but even a simple switch/case on error codes in your Node code can implement it.
Timeouts as errors: When waiting on an async step (like a Kafka response), a timeout is effectively an error condition. Classify timeouts as transient or permanent wisely. A single timeout might warrant a retry of the message or extending the wait, but repeated timeouts likely mean the service is down or slow (semi-permanent issue), and you should fail the saga.
Compensation failure handling: One often overlooked scenario is: what if a compensating action fails? For example, the Payment refund endpoint might itself error out (maybe the payment gateway is down). Now you’re in a tough spot: the saga’s attempt to rollback has failed. Automated retry can help here too – you should certainly retry compensations a few times if they fail, because you really want them to succeed to restore consistency. If after retries a compensation still fails, the orchestrator should log a critical alert (this often requires manual intervention, like an admin to sort out the inconsistency later). But having at least a retry on compensations is important; they’re just as prone to transient issues. In your Saga Log, mark that compensation “PaymentRefund” is pending retry, and possibly have a background job or the orchestrator itself keep trying even after the saga officially fails (this starts to look like a workflow engine which would have a schedule to retry compensations). At minimum, alert someone if a compensation cannot be completed so the data inconsistency can be addressed.
Example in code: To illustrate, consider how we might handle a call in code with classification:
try {
const response = await callWithRetry({ method: 'post', url: paymentURL, data: paymentPayload });
if (response.status === 200) {
// Payment succeeded
} else {
// Payment responded with an error status
if (response.status === 402) {
throw new SagaBusinessError('PaymentDeclined');
} else {
throw new Error('Payment service error ' + response.status);
}
}
} catch (err) {
if (err instanceof SagaBusinessError) {
// No retry, immediately initiate compensation for earlier steps
throw err;
}
// If we reach here, err is likely a network or unknown error that persisted after retries
throw err;
}
In this snippet, a custom SagaBusinessError is used to tag known business failures (like a payment decline) so that elsewhere in the orchestrator’s catch, we know not to retry that, whereas other errors were already retried in callWithRetry. This separation of concerns simplifies the logic.
Summing up, advanced error handling in sagas means being smarter than “catch and compensate everything the same way.” By classifying errors and automating retries with backoff for the right cases, you can greatly increase the success rate of sagas in face of transient problems. Real-world networks and systems are unreliable – timeouts and glitches happen – so a saga that never retries is often too fragile. On the other hand, infinite or blind retries can cause other problems, so we introduced circuit breakers and limits to avoid runaway retries. The orchestrator essentially implements a mini resilience policy for each step. Combined with the observability above (so you can monitor retry rates, etc.), this leads to sagas that are self-healing for temporary faults and quick to fail for permanent ones, which is exactly what you want in a reliable distributed transaction system.
Conclusion
Expanding a Saga orchestrator beyond the basics involves careful consideration of software design and operational practices. We began with the simple Node.js Saga pattern – an Express/Axios-driven orchestrator coordinating microservice calls – and evolved it into a production-grade saga orchestration framework. Along the way, we identified where existing content often stops short and filled those gaps with advanced techniques:
- We introduced pluggable middleware hooks for the orchestrator, enabling audit logs and metrics collection to be added modularly, providing transparency and measurability to the Saga’s execution. This addresses the need for clear visibility and extensibility in the orchestrator’s design (something often missing in simple code examples).
- We explored dynamic saga definitions, allowing saga flows to be defined in configuration or a database. This brings flexibility and easier maintenance at scale, though it requires disciplined versioning and validation. It’s an area rarely covered in tutorials, but it moves a Node.js orchestrator closer to the capabilities of enterprise workflow engines.
- We showed how to integrate asynchronous messaging (e.g., Kafka) within an orchestrated saga without abandoning the orchestration approach. This hybrid model leverages the reliability of messaging for certain steps while keeping central control, combining the strengths of both orchestration and choreography. As sources suggest, many real systems adopt a hybrid of simple flows via choreography and complex ones via orchestration – our discussion provides a blueprint for doing both within a single saga.
- We emphasized testing and fault injection for saga rollback logic, advocating for systematic failure scenario tests. This ensures that compensating transactions aren’t just theoretical but proven to work under various failure modes. By actively testing these scenarios in CI and staging (even using chaos engineering techniques), you can prevent nasty surprises in production.
- We covered CI/CD best practices around sagas, such as versioning flows, coordinating deployments to avoid breaking changes, and monitoring new releases carefully. Given the orchestrator’s central role, treating its changes with care (like API changes) and using strategies like canary deployments and backward compatibility can save you from data consistency incidents.
- We delved into observability, urging a comprehensive approach: structured logs with correlation IDs for traceability, distributed tracing for end-to-end visualization, and custom metrics for monitoring saga health. With these in place, operators can debug issues in a fraction of the time and spot trends (e.g., a rising compensation rate) before they become problems.
- Finally, we refined error handling by classifying errors and using targeted retries. We cited recommendations to handle transient failures with retries and backoff and to design idempotent operations so that retries and compensations don’t introduce side effects. By incorporating circuit breakers and careful checks, the orchestrator can avoid needless failures and also avoid overwhelming services during outages.
Bringing these enhancements together, you can transform a basic Node.js saga orchestrator into a robust orchestration service suitable for complex, high-reliability microservice systems. You’ll have an orchestrator that not only coordinates distributed transactions, but also provides observability into those transactions, tolerates and recovers from failures gracefully, and can be evolved over time without downtime. Importantly, we achieved this while preserving the familiar Node.js stack (Express for endpoints, Axios for calls, and popular Node libraries for messaging and logging) – demonstrating that you don’t necessarily need a heavy workflow engine to implement these patterns.
That said, it’s worth acknowledging that there are battle-tested frameworks (Temporal, Camunda, Conductor, etc.) that inherently provide many of these features (like state management, retries, tracing) out of the box. Teams should weigh the build vs. buy decision. Our exploration here empowers you with knowledge of how these concerns can be addressed in a custom implementation. Even if you eventually adopt a framework, understanding these underlying mechanisms will help in configuring and using such tools correctly.
In conclusion, the Saga pattern remains a powerful solution for distributed transactions in microservices, but the devil is in the details. By addressing the oft-neglected areas – middleware extensions, dynamic configurability, async integration, rigorous testing, deployment strategy, observability, and nuanced error handling – you can take the Saga pattern from a theoretical idea to a practical, reliable backbone of your microservices architecture. The end result is a system where business processes execute reliably across services, failures are contained and compensated, and engineers have the insight and control needed to maintain data consistency with confidence.
Have you faced a cross-service transaction failure? Your insights and experiences are welcome—let’s discuss in the comments!
Sources:
- Chameera Dulanga – Implementing Saga Pattern in a Microservices with Node.js
- Cloudnweb – Implementing Saga Pattern in Nodejs Microservices
- Quang Le – The beauty of Orchestration Saga in Microservices
- Federico Bevione – Transactions in Microservices: Part 1 – SAGA Patterns overview
- Dinesh Arney – Implementing the Saga Pattern using Choreography and Orchestration
- Sapan Kumar Mohanty – Choreography vs. Orchestration in Microservices: Which Saga Strategy Should You Choose?
- Chris Richardson – Pattern: Saga